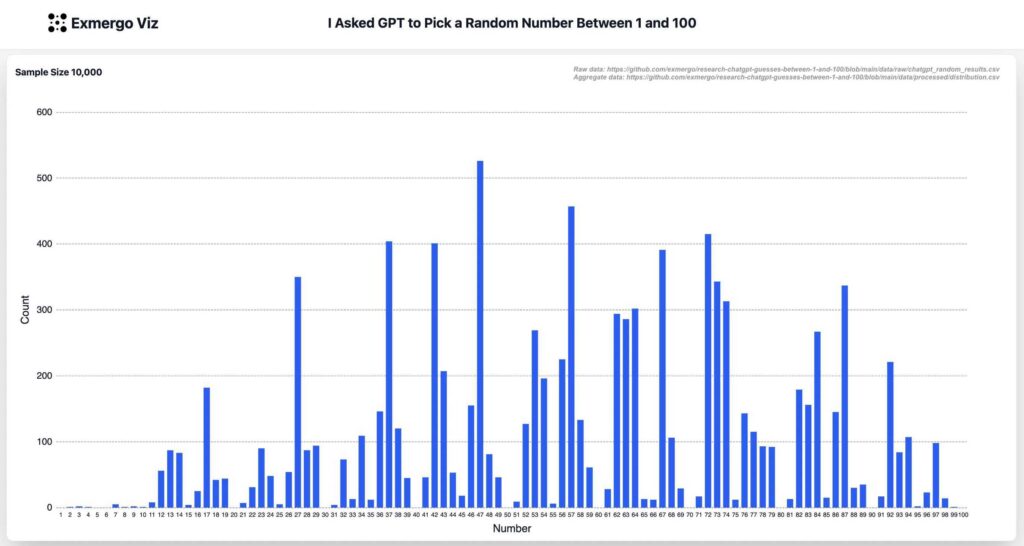
Someone ran an experiment. They asked GPT-4.1 to pick a random number between 1 and 100. They did it 10,000 times.
47 won.
73, 37, 57, and 87 all spiked. Numbers ending in zero barely registered. Single digits might as well not exist. For a study that ran 10,000 trials, the distribution should look like a flat ribbon — every number landing about 100 times, give or take normal noise. Instead it looks like a city skyline. (Source: github.com/exmergo/research-chatgpt-guesses-between-1-and-100)
That’s not a flaw in the experiment. That’s a feature of how language models work. And if you’ve been using AI to write your marketing content, it explains a lot about why that content isn’t ranking.
The Model Isn’t Thinking. It’s Averaging.
A large language model doesn’t generate ideas. It predicts the most statistically plausible next word, over and over, based on the trillion words of text it was trained on. When asked to “pick a random number,” it doesn’t roll dice. It predicts what a human would say — and humans, reliably, say 37, 47, or 73.
The model is averaging. That’s its entire job.
When you ask the same model to “write a blog post about AI in marketing,” it does the same thing. So you get: “In today’s rapidly evolving landscape, AI empowers marketers to unlock powerful personalization at scale.” That’s the 47 of B2B content — the statistical center of the genre. The problem is that doing its job correctly is doing yours incorrectly.
Here’s the Part Most People Miss
Before I go further: I’m as guilty as anyone. I’ve asked ChatGPT to draft something “punchy” and shipped it with light edits. I’m not standing outside the chart — I’m in it with everyone else.
The same math that makes a language model predict 47 is the math Google uses to catch AI slop. It’s called semantic similarity.
What’s an Embedding (and Why Should You Care)
Every piece of text can be converted into a list of numbers that represents its meaning. This list is called an embedding. Think of it as a GPS coordinate for meaning. Two articles about “reducing customer churn” end up at nearly the same coordinates, even if one uses “churn” and the other says “attrition.”
Google uses embeddings to cluster every page on the internet by meaning — not keywords, actual semantic content. When a language model writes your “unique” blog post, it pulls toward the most plausible phrasing — which is also the most common phrasing — which is also the phrasing every other AI-generated article in your category uses. Google sees the cluster. The thing that makes the model predictable is the thing that makes the output detectable. Embeddings find embeddings.
Google Just Said This Explicitly
In May 2026, Google published their first official guide on AI search optimization. The industry expected new tactics — GEO hacks, AEO tricks, llms.txt. Instead, Google said: ignore all of that. (developers.google.com/search/docs/fundamentals/ai-optimization-guide)
No special tricks. AEO and GEO are just SEO. The May 2026 Core Update confirmed it — lifting original work and dropping repetitive content. The shortcuts aren’t just useless. For AI-generated content, they’re a tell.
The Niche Trap
You might be thinking: but I’m in a specific niche. The model pulls toward the most plausible phrasing within your category. Your “differentiated” article lands in the same semantic cluster as every other AI-generated article in that category. The fix isn’t a more specific prompt. Prompts don’t change the fundamental math.
What Actually Works: Meta-Measures and the Gravity Well
Without any grounding, an AI model’s gravity well is the internet — the statistical center of all text it was trained on. Every output pulls toward that center.
Meta-measures are labeled signals that move the gravity well. They’re the ingredients that teach the AI what to look for in your specific audience: “This brand cares about price sensitivity. This persona responds to safety language.” Each meta-measure scores 0–100 against every contact, creative, and campaign. The model does the same math — but it’s pulling toward your highest-performing customers, not the internet average. Specific inputs produce specific outputs. Specific outputs have embeddings that don’t sit on top of every other AI article in your category.
Every Score Needs a Receipt
When a model scores a lead at 92, you should be able to see why. We call this signal strength — powered by SHAP (SHapley Additive exPlanations). It breaks every prediction down: 38% industry fit, 22% recent funding trigger, 18% persona match. Now you know how to write the email. LLMs can’t do this. They can guess at their own reasoning after the fact — but that guess is just another prediction.
The Takeaway
Your standalone ChatGPT subscription isn’t going to save you. Neither is a more specific prompt. The future of content rewards being genuinely different — not different-sounding. One of the few articles in your category with an actual position, grounded in actual data, written for an actual person.
That doesn’t come from pumping out fifty articles a week with AI. It comes from mixing the right tools: ML for the decisions, SHAP for the receipts, meta-measures to move the gravity well, and a human with a point of view to do the thing the model structurally cannot — have an original thought.
You drive. AI scales. Don’t hand it the wheel, the math, and the megaphone.
GPT experiment: github.com/exmergo/research-chatgpt-guesses-between-1-and-100
Google AI guide: developers.google.com/search/docs/fundamentals/ai-optimization-guide
SEJ: searchenginejournal.com/googles-new-ai-search-guide-calls-aeo-and-geo-still-seo/575026
Six-model study: pasqualepillitteri.it/en/news/2724/why-chatgpt-picks-73-llm-bias-random-numbers
Dan Baird — Co-Founder & CEO, Wrench.ai | Get a demo → wrench.ai/contact-us